Project
●Vision Transformer Quantization — INT8 DINOv2-seg
keywords: DINOv2, Vision Transformer, ViT-S/B/L 14, semantic segmentation, ADE20K, post-training quantization, SmoothQuant, int8 W8A8, activation outliers
date: Feb.2026
We applied int8 post-training quantization to DINOv2 segmentation backbones (ViT-S/14, ViT-B/14, ViT-L/14) with both linear and multiscale (ms) heads, and measured mIoU on the full ADE20K validation set (2000 images). The interesting story is on the larger backbones: plain int8 PTQ catastrophically collapses on ViT-B/14 and ViT-L/14, and SmoothQuant fixes it — the textbook ViT activation-outlier failure mode, made visible on a real CV benchmark.

Float32 (left) vs INT8 PTQ (right) ADE20K segmentation predictions on two ADE20K validation images.
Quantization granularity (same across all runs)
- Linear weights — per-channel symmetric
- Linear activations — per-tensor asymmetric
- SDPA Q / K — per-tensor symmetric (
--sdpa_sym, TRT-LLM-compatible) - SDPA V — per-head symmetric (free; each head is an independent GEMM)
Methods tried
- Plain PTQ — no SmoothQuant, single-pass calibration, per-tensor activation min/max.
- SmoothQuant — two-pass calibration.
sq-ph (per-head SDPA SmoothQuant) was not run here — SDPA Q/K/V are already independently quantized in the SmoothQuant Basic config, so the gap on segmentation backbones is expected to be small.
Results — mIoU on ADE20K val
| Variant | Head | Float | sq α=0.5 | sq Δ | ptq | ptq Δ |
|---|---|---|---|---|---|---|
| vits14 | linear | 44.76 | 44.66 | −0.10 | 44.51 | −0.25 |
| vits14 | ms | 45.89 | 45.90 | +0.01 | 45.71 | −0.18 |
| vitb14 | linear | 47.83 | 47.84 | +0.01 | 7.38 | −40.45 |
| vitb14 | ms | 48.92 | 48.60 | −0.32 | 8.84 | −40.08 |
| vitl14 | linear | 47.89 | 46.87 | −1.02 | 13.44 | −34.45 |
| vitl14 | ms | 49.98 | 49.29 | −0.69 | 17.34 | −32.64 |
Pink-highlighted rows are where plain PTQ collapses by 30+ mIoU points. SmoothQuant recovers all of them to within ~1 pt of float.
Findings
- SmoothQuant α=0.5 is essentially free on ViT-S/14 and ViT-B/14 (Δ ≤ 0.32 pt), and within ~1 pt on ViT-L/14. With the multiscale head, all three sizes lose less than 0.7 pt vs float — production-deployable.
- Plain PTQ catastrophically collapses on ViT-B/14 and ViT-L/14 — mIoU drops by 30–40+ points. Post-GELU activations in the MLP of larger ViTs contain extreme outliers (>10× the bulk distribution) that per-tensor int8 cannot represent. SmoothQuant migrates the outlier difficulty into the weights, where per-channel quantization handles it cleanly.
- ViT-S/14 survives plain PTQ (−0.25 on linear, −0.18 on ms) because its activation distributions are narrower — the outlier channels haven't built up yet. This is not a general escape, just a property of the smallest variant. Don't generalise it.
- Linear vs multiscale head are quantization-symmetric — both heads show the same Δ-pattern under each recipe. The head choice affects baseline mIoU, not quantization sensitivity.
Practical takeaway
For int8 deployment of DINOv2 segmentation, SmoothQuant is not optional on B/14 or L/14. The symmetric Q/K/V constraint we adopted (TRT-LLM-compatible) costs essentially nothing on these models, so the same recipe is portable to TensorRT-LLM-style runtimes without an accuracy retraining loop. Concretely: --ptq sq --alpha 0.5 --sdpa_sym is the right default for all three sizes.
Diagnosing Transformer Quantization Failures
keywords: ViT, DINOv2, depth, segmentation, activation outliers, SmoothQuant, per-tensor quantization, sensitivity analysis
date: Feb.2026
This is the diagnostic follow-up to P30 (DINOv2-seg int8 PTQ). I noticed that standard INT8 PTQ collapses for both DINOv2-Depth ViT-B / ViT-L and DINOv2-seg ViT-B / ViT-L, while SmoothQuant α=0.5 stays within ~1 mIoU point of float. The natural question is why — this post visualizes per-channel / per-token activation magnitudes to show what plain PTQ actually breaks, and what SmoothQuant repairs.
What we visualized
For a few interesting layers, we plot |output| as a (token, channel) 3D surface under three model states:
- FP32 — the reference distribution.
- SmoothQuant α=0.5 + symmetric Q/K/V.
- Plain PTQ + symmetric Q/K/V.
Key finding: outliers are preserved — the bulk distribution is what gets damaged
Across all the layers we inspected, the outlier spikes look almost identical in all three states. The real damage is in the noise floor. In deep ViT blocks, a small number of activation values reach ~40, forcing a per-tensor INT8 step of roughly:
40 / 127 ≈ 0.31
Every "normal" activation below ±0.31 then rounds to 0 or to ±0.31. Empirically this raises the activation noise floor by 18–26%, and it is this loss of bulk precision — not the rare outlier itself — that explains why mIoU collapses from ~48 to ~8 on ViT-B/14.
SmoothQuant fixes this by migrating channel-wise activation outliers into the weights, where per-channel int8 quantization handles them cleanly. The activation distribution that the per-tensor scale has to cover becomes balanced again, and the bulk precision is preserved.
A blind spot in weight-only sensitivity analysis
An important methodology observation: our SQNR sensitivity analyzer only quantizes weights, so it ranked shallow mlp.fc2 layers as the "most sensitive" ones. A direct activation-outlier ranker instead identified deep blocks — specifically block.8.mlp.fc2 and block.11.mlp.fc2 — where the actual PTQ failure is happening. Sensitivity analysis for transformer PTQ should include an activation-quantization mode, otherwise the failure-driving layers are invisible to it.
Take-aways
- ViT PTQ failure is primarily activation-side, not weight-side.
- The outlier itself is preserved; the bulk activations lose precision because the per-tensor scale is dictated by the outlier.
- SmoothQuant works by making per-tensor activation quantization viable again — it does not "delete" the outlier, it relocates it.
- Sensitivity analysis should include an activation-quantization mode; weight-only SQNR will mis-rank the failure-driving layers.
Case study 1: block.11.mlp.fc2 — the canonical PTQ failure
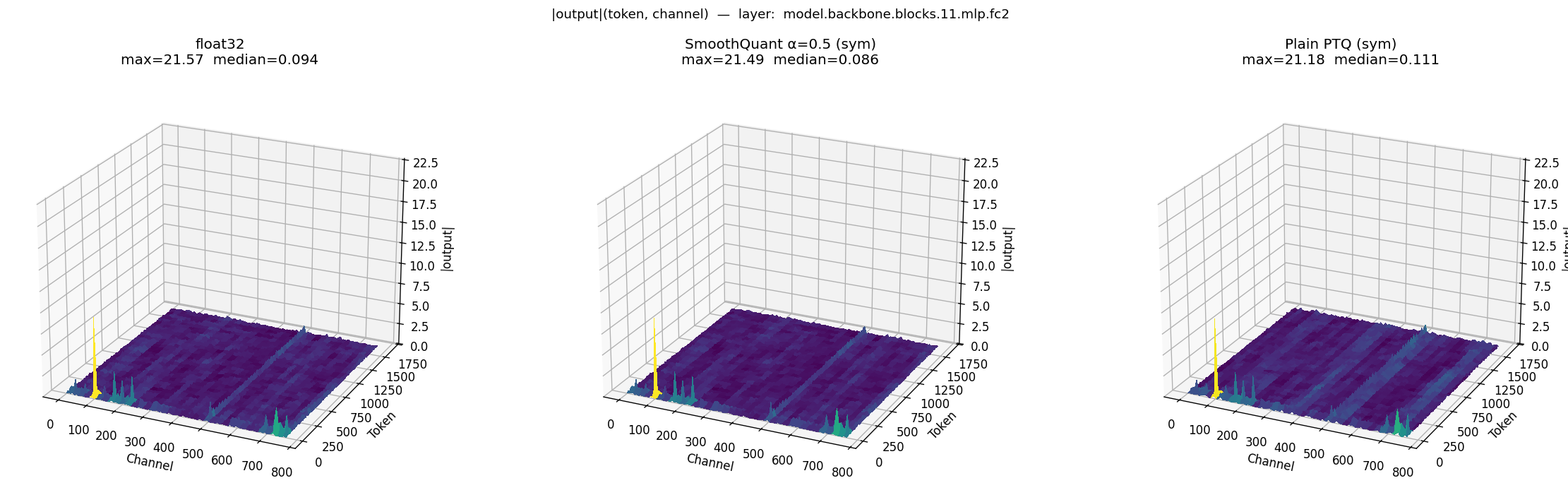
|output|(token, channel) at model.backbone.blocks.11.mlp.fc2. Left: FP32 (max=21.57, median=0.094). Middle: SmoothQuant α=0.5 sym (max=21.49, median=0.086). Right: Plain PTQ sym (max=21.18, median=0.111).
block.11.mlp.fc2 clearly exposes the PTQ failure mode. Its large activation outliers set a coarse per-tensor INT8 scale, so values in the dense near-zero region are heavily rounded or shifted. The outlier peak is preserved, but the bulk activation distribution is distorted — reflected by the median rising from 0.094 to 0.111 (+18%). SmoothQuant avoids this by reducing the activation-side channel imbalance, and the median stays close to the FP32 reference (0.086 vs 0.094).
Case study 2: block.3.attn.qkv — large outlier, but PTQ doesn't fail
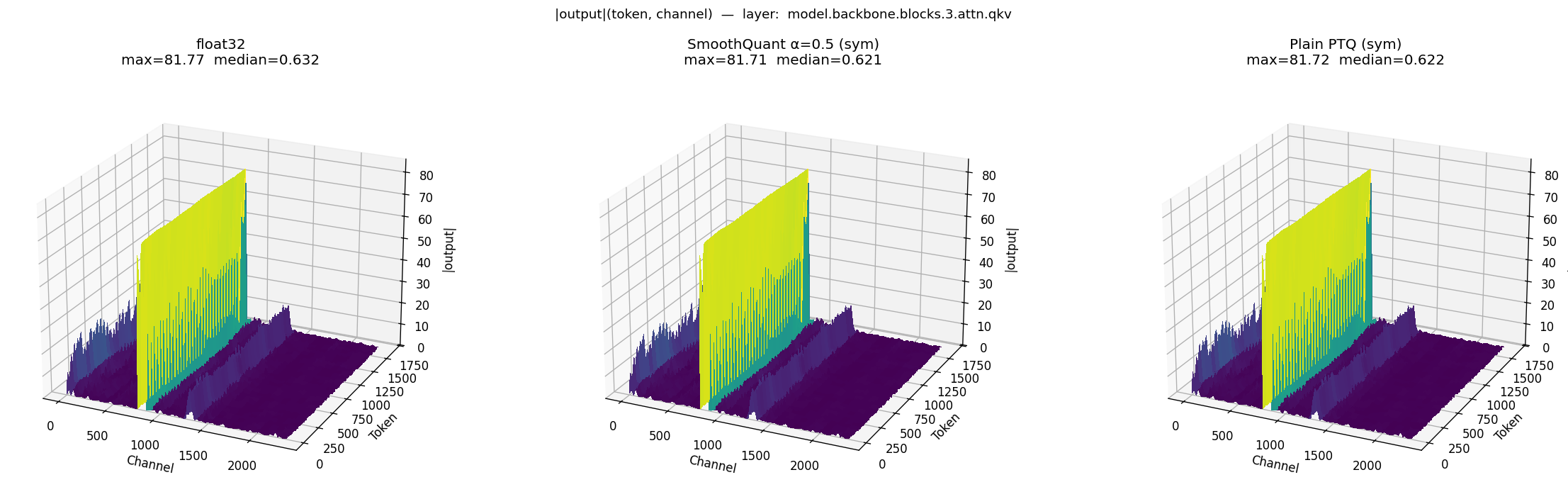
|output|(token, channel) at model.backbone.blocks.3.attn.qkv. Left: FP32 (max=81.77, median=0.632). Middle: SmoothQuant α=0.5 sym (max=81.71, median=0.621). Right: Plain PTQ sym (max=81.72, median=0.622).
block.3.attn.qkv tells a very different story. It contains a large, highly structured activation ridge with a maximum around 82, yet both max and median remain almost identical across all three model states. Despite ranking highly by max / median ratio, this layer shows little visible PTQ distortion. The lesson: a large outlier ratio alone is not sufficient to predict quantization failure — the location, structure, and downstream propagation of the outliers also matter. A confined ridge in an attention QKV projection is not the same kind of problem as a sparse spike on top of a dense post-GELU MLP distribution.
Companion: P30 — DINOv2-seg int8 PTQ benchmarks (the mIoU collapse this post diagnoses).