Project
MobileNet Per-Channel vs Per-Tensor Quantization
keywords: int8 quantization, per-channel quant, per-tensor quant, MobileNetV3
date: November.2022
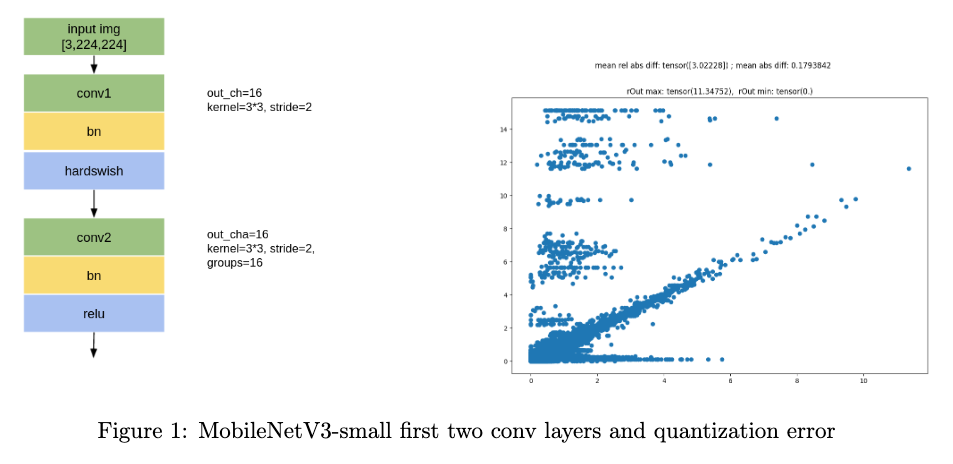
MobileNet Quantization
Update later
Quantization error analysis and comparison between per-channel and per-tensor quantization on MobileNetV3.
Qwen3 LLM Quantization
keywords: Qwen3-0.6B-Base, LLM, post-training quantization, SmoothQuant, MeanShift, FP8 E4M3, MXFP8, int8 W8A8, WikiText-2 perplexity
date: Jan.2026
This post benchmarks every PTQ method I considered for the Qwen3 decoder on a single small model — Qwen3-0.6B-Base — using perplexity (PPL) on WikiText-2 with 1000 calibration samples. Weights and activations are both 8-bit (W8A8) for int8 rows; FP8 / MXFP8 rows use 8-bit float formats. The goal is to isolate which design choices are essential versus merely convenient. The model is the Qwen3-Base 0.6B checkpoint — not to be confused with Qwen/Qwen3.5-0.8B-Base, which is a different architecture (covered in the size-scaling post).
Methods at a glance
- Best int8 (accuracy): SmoothQuant on linear layers, asymmetric activation quantization with a per-token scale (dynamic at decode time), and a separate int8 scale per attention head for Q, K, V — with online softmax in the int8 attention path.
- Coarser int8 (static activations): Same SmoothQuant and per-head Q/K/V, but activations use a single per-tensor calibrated scale instead of per-token.
- Basic SmoothQuant + coarse attention quant: SmoothQuant on linears, per-tensor Q and K, per-output-channel V — cheap to describe, much worse PPL on small models.
- Plain int8 PTQ (no SmoothQuant): Standard W/A int8 without migrating outliers from activations to weights — fails on these LLMs.
- FP8 E4M3: 8-bit float W/A with a range wide enough that SmoothQuant is unnecessary; often paired with MeanShift (subtract per-channel Q/K input mean, fold into bias) for symmetric quant.
- Faster int8 (symmetric Q/K/V): Same SmoothQuant and per-token activations, but Q/K/V use symmetric int8 so softmax avoids zero-point algebra — much worse PPL on 0.6B; traded for kernel simplicity.
Why PPL
Perplexity is a coarse but reproducible stress test for weight + activation quantization across the entire decoder. The pattern that emerges on this checkpoint: SmoothQuant + fine-grained activation and attention quant makes int8 usable, while FP8 E4M3 with MeanShift on Q/K is simpler and edges out the best int8 line on this small model. PPL is necessary but not sufficient — downstream-task results are in a separate post.
Recommended high-level recipes
| Priority | Linears + activations | Attention Q/K/V | Qwen3-0.6B PPL | Notes |
|---|---|---|---|---|
| FP8 (best accuracy) | FP8 E4M3, W per-out-channel, X per-tensor | FP8 per head + MeanShift on Q/K inputs | 10.98 (+0.46%) | No SmoothQuant. |
| Int8 (best int8) | SmoothQuant + asymmetric per-token dynamic acts | Asymmetric per head + online softmax | 11.70 (+7.0%) | SmoothQuant is essential. |
| Faster int8 | SmoothQuant + per-token dynamic acts | Symmetric per head + online softmax + MeanShift | 15.85 (+45%) | Simpler SDPA; large PPL hit at 0.6B. |
- E4M3's wide float8 range absorbs activation outliers; stacking SmoothQuant on top of FP8 tends to hurt — SmoothQuant pushes weights past the representable range and the model diverges.
- MeanShift on Q/K: per-channel means are folded into the bias, so there is no extra runtime cost; it roughly halves the FP8 PPL error at 0.6B (~+1.0% → +0.46%).
Int8 ablation on Qwen3-0.6B-Base (SmoothQuant α = 0.65)
| Method | PPL | vs FP32 |
|---|---|---|
| FP32 baseline | 10.93 | — |
| Per-token dynamic acts + per-head Q/K/V (fake) | 11.71 | +7.1% |
| Per-token dynamic acts + per-head Q/K/V (real int8 matmuls) | 11.70 | +7.0% |
| Static per-tensor acts + per-head Q/K/V (fake) | 12.68 | +16.0% |
| Static per-tensor acts + per-head Q/K/V (real int8) | 12.67 | +15.9% |
| Static per-tensor acts + per-tensor Q/K + per-channel V (fake) | 30.37 | +177.9% |
| Static per-tensor acts + per-tensor Q/K + per-channel V (real int8) | 30.50 | +179.1% |
Takeaway: per-token activation scaling plus per-head attention quant holds most of the quality at 0.6B. Fake-quant vs real int8 differs by only ~0.01 PPL — the convert-to-real-int8 pass is essentially free of additional accuracy loss.
FP8, MXFP8 and MeanShift on Qwen3-0.6B-Base
| Method | PPL | vs FP16 | SmoothQuant? | MeanShift? |
|---|---|---|---|---|
| FP16 baseline | 10.93 | — | — | — |
| FP8 E4M3 + MeanShift (Q/K) | 10.98 | +0.46% | No | Yes |
| FP8 E4M3, no MeanShift | 11.04 | +1.0% | No | No |
| MXFP8 E4M3, block 32 | 11.04 | +1.0% | No | No |
| MXFP8 E4M3 + MeanShift | 11.04 | +1.0% | No | Yes |
| Best int8 (SmoothQuant + per-token + per-head) | 11.70 | +7.0% | Yes | No |
| Int8, static per-tensor acts + per-head Q/K/V | 12.67 | +16% | Yes | No |
| Int8, symmetric Q/K/V + MeanShift | 15.85 | +45% | Yes | Yes |
| Int8, symmetric Q/K/V, no MeanShift | 16.40 | +50% | Yes | No |
| Int8, static per-tensor everything (weak line) | 30.50 | +179% | Yes | No |
| FP8 E4M3 + SmoothQuant | diverged | — | Yes | No |
| FP8 E3M4 | 33973 | diverged | No | No |
| Int8, no SmoothQuant | 30.50 | +179% | No | No |
- E4M3 + MeanShift is the accuracy sweet spot at 0.6B.
- MeanShift does not help MXFP8 — per-block scales already adapt to channel statistics.
- E3M4 (max=15.5) is too narrow for LLM activations and diverges.
- Symmetric int8 in attention remains far worse than asymmetric int8 — the zero-point matters.
Grouped-query attention (GQA)
Qwen3-0.6B uses fewer KV heads than query heads; in deployment, K/V (and their per-head scales) are replicated to match the query head layout so each head's matmul sees consistent shapes.
Pipeline
- Prepare the model with inserted fake round-trip quant nodes on matmuls and attention.
- Calibrate. SmoothQuant: two passes on calibration text — first collects activation magnitudes, then migrates them into the weights and quantizes. FP8: single pass per the recipe.
- Optionally convert to real int8 matmuls (W and X int8, int32 accumulator).
- Optionally compile / fuse for inference.
Method-level take-aways
- FP8 E4M3 with MeanShift on Q/K is the strongest line at 0.6B (+0.46% PPL) — E4M3's wide float8 range absorbs activation outliers without SmoothQuant.
- SmoothQuant + per-token activations + per-head asymmetric Q/K/V is the best int8 recipe (+7.0% PPL).
- Real int8 tracks fake-quant within ~0.01 PPL — once the recipe is right, the runtime conversion is essentially lossless.
- Plain int8 without SmoothQuant is unusable (+179% PPL); outlier migration from activations to weights is non-negotiable.
- Symmetric Q/K/V costs roughly +38% PPL at 0.6B — a steep kernel-simplicity tax that may be worth it on hardware that requires symmetric formats (e.g., TRT-LLM).
Continued in the next post: how the best recipes scale across the rest of the Qwen3 family (1.7B / 4B / 8B / 14B) and how Qwen3.5-0.8B compares.
Qwen3 Quantization Scaling: 0.6B–14B
keywords: Qwen3, Qwen3.5, LLM, post-training quantization, SmoothQuant, int8 W8A8, WikiText-2, scaling, perplexity
date: April.2026
The companion to the previous post: take the winning int8 recipes from Qwen3-0.6B and run them across the rest of the family — 1.7B, 4B, 8B, 14B — plus the cousin Qwen3.5-0.8B-Base (a different architecture, dispatched to AxQwen3_5ForCausalLM in our codebase). Same harness (WikiText-2 perplexity, 1000 calibration samples), same recipes; only the model and the SmoothQuant migration strength α change. Question: does the 0.6B method ranking still hold at scale, and how big is the int8 vs float gap as the model grows?
Per-model results (α = 0.8 throughout)
Each method has two sub-columns: fake (int8 simulated in fp32 math) and real (actual int8×int8 matmul via torch._int_mm). Numbers are WikiText-2 PPL; small text below each value is the relative gap vs the float baseline.
| Series | Model | Baseline (float) | Best int8 (per-token + per-head Q/K/V) | Static per-tensor acts + per-head Q/K/V | Static per-tensor acts + per-tensor Q/K | No SmoothQuant (plain int8 PTQ) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| fake | real | fake | real | fake | real | fake | real | |||
| Qwen3.5† | 0.8B | 11.30 (FP32) | — | — | 11.54 +2.1% | — | — | — | — | — |
| Qwen3 | 1.7B | 8.27 (FP32) | 8.57 +3.6% | 8.58 +3.7% | 8.76 +5.9% | 8.77 +6.0% | 9.85 +19.1% | 9.84 +19.0% | 49.79 +502% | 49.80 +502% |
| Qwen3 | 4B | 6.97 (FP16) | 7.10 +1.9% | 7.09 +1.7% | 7.30 +4.7% | 7.29 +4.6% | 7.31 +4.9% | 7.31 +4.9% | 13.97 +100% | 13.96 +100% |
| Qwen3 | 8B | 6.19 (FP16) | 6.29 +1.6% | 6.29 +1.6% | 6.47 +4.5% | 6.47 +4.5% | 6.51 +5.2% | 6.51 +5.2% | 13.86 +124% | 13.86 +124% |
| Qwen3 | 14B | 5.66 (FP16) | 5.75 +1.6% | 5.75 +1.6% | 5.90 +4.2% | 5.89 +4.1% | 5.89 +4.1% | 5.89 +4.1% | 12.57 +122% | 12.62 +123% |
† Qwen3.5-0.8B is a different architecture from the Qwen3 series; only one cell (static per-tensor + per-head, fake-quant) has been measured for this checkpoint so far. Empty cells (—) for 0.8B mean "not yet run", not "diverged".
Cross-size summary (best int8 line)
Reading just the highlighted "per-token + per-head Q/K/V" column out of the table above gives the cleanest picture of how the same int8 recipe behaves as the model grows:
| Series | Model | Float baseline PPL | Best int8 PPL | ΔPPL (%) |
|---|---|---|---|---|
| Qwen3 | Qwen3-0.6B | 10.93 (FP32) | 11.70 | +7.0% |
| Qwen3.5† | Qwen3.5-0.8B | 11.30 (FP32) | 11.54 (fake only, static per-tensor) | +2.1% |
| Qwen3 | Qwen3-1.7B | 8.27 (FP32) | 8.58 | +3.7% |
| Qwen3 | Qwen3-4B | 6.97 (FP16) | 7.09 | +1.7% |
| Qwen3 | Qwen3-8B | 6.19 (FP16) | 6.29 | +1.6% |
| Qwen3 | Qwen3-14B | 5.66 (FP16) | 5.75 | +1.6% |
† For Qwen3.5-0.8B the ΔPPL is from the static per-tensor recipe rather than the best-int8 line, since per-token + per-head has not yet been measured for this checkpoint.
Take-aways
- Larger Qwen3 models quantize more easily. The best-int8 PPL gap shrinks from +7.0% on 0.6B to about +1.6% from 4B onwards — the same recipe gets monotonically better as the network grows.
- The recipe ranking is stable across sizes. Per-token + per-head Q/K/V wins; static per-tensor with per-head Q/K/V is second-best; coarser attention quant (per-tensor Q/K) costs another ~5%; no SmoothQuant blows up by +100% to +500% on every size.
- Real int8 tracks fake-quant within ~0.02 PPL at every size — once the recipe is correct, deploying real int8 is essentially free of additional accuracy loss.
- SmoothQuant α grows with the model: 0.65 was best on 0.6B, 0.8 was the right setting from 1.7B onwards — bigger models benefit from migrating more activation magnitude into the weights.
- Qwen3.5-0.8B is a friendly outlier. +2.1% on a recipe that costs Qwen3-0.6B +16% — likely an architecture effect from the different (Qwen3.5) backbone. Worth a fuller recipe sweep on this checkpoint.
Coming next: results on downstream benchmarks (MMLU, HellaSwag, GSM8K, IFEval) using the same best-int8 recipe, where the per-tensor Q/K collapse from PPL shows up as actual generation-accuracy failures.