Project
Intelligent Game "Omega"
keywords: AI Player, Board Game, Alpha-Beta Search, Union-find Algorithm, Pygame
date: Sep.2018

Omega is an AI board game built on the Alpha-Beta Search framework. The game board comprises a fixed number of hexagonal grids, determined by the initial board size setting. In the accompanying figure, the board size is 5, meaning the distance from the center to any outer hexagon is 5. Each player is assigned either White or Black stones. Stones of the same color that are connected form a group. The score for each player is calculated by multiplying the number of stones in each group. For instance, the White player has three separate groups with 3, 7, and 5 stones respectively, resulting in a score of 3*7*5 = 105.
Each round consists of two turns: one for the player and one for the AI. During each turn, the player (or AI) first places their own stone and then places a stone for their opponent. The game ends when there is no longer enough space to complete a full round. The player with the higher score at the end wins.
Cleaning Robot from Genetic and Evolutionary System
keywords: Evolutionary Robotic System, Genetic Algorithm, Robotic ICC Kinematic System, Robot Controller
date: Feb.2019
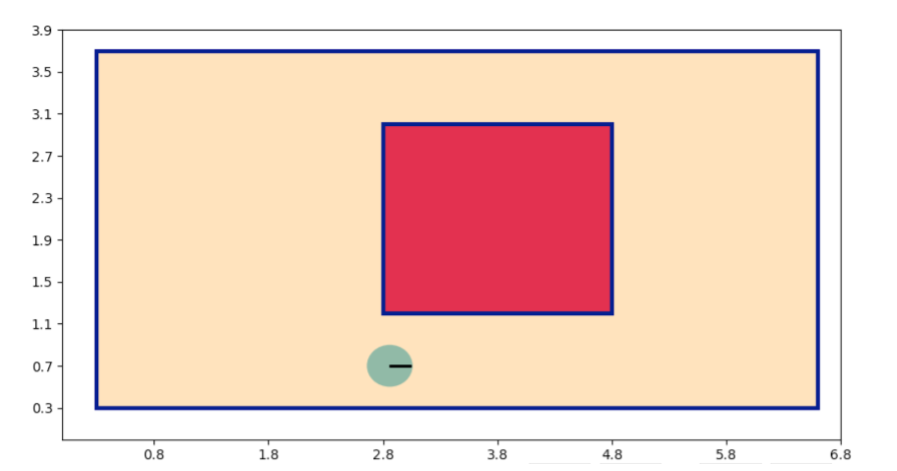
This project is a software simulation of a cleaning robot. In the figure, the yellow areas represent dirty spots, while the pink areas denote obstacles. The robot is designed to automatically clean the room efficiently and avoid obstacles.
My robot operates using a Recurrent Neural Network (RNN) for control. Its controller is derived from an evolutionary system that runs for 400 generations. Each generation consists of 60 individuals, each with a lifespan of 30 seconds. The entire evolution process takes approximately 48 hours.
Unlike deep learning models, the evolutionary process can be viewed as reinforcement learning for the entire system. At the start of each generation, the system selects the top k individuals from the previous generation based on their performance, while the remaining individuals are eliminated. These k individuals reproduce by exchanging portions of their genomes to create new individuals. All the offspring then operate, and after their lifespan, the system records their performance and prepares for the next generation. After several hundred generations, this process should produce a qualified cleaning robot.
Reconstructing Image by Neural Style Transfer Learning based on Pre-trained VGG16 Neural Network
keywords: Deep Learning Implementation, Convolutional Neural Network, Computer Vision, Neural Style Transfer Learning, Gradient Descent, Tensorflow
date: May.2019

Deep Convolutional Neural Networks (such as the VGG series, AlexNet, ResNet, and Inception) have proven highly effective in tasks like image classification and recognition. Interestingly, they can also be leveraged for creative tasks like learning image styles. By feeding two images into the model—one as the "content image" and the other as the "style image"—the model blends features from both to generate a new image. For example, the "Candy Tiger" and "Starry Lion" shown in the figure are results of this process.
This project utilizes a pre-trained VGG16 model, which consists of five convolutional blocks. In each block, the output from the first layer is extracted as the style target, while the second convolutional layer's output from the fifth block is used as the content target. During training, the model follows two key steps: 1) it performs gradient descent to minimize the "content difference" (between the new image and the content image) and the "style difference" (between the new image and the style image); 2) it updates the image using the newly computed gradients. After several epochs (100 in this case), the model produces a stunning image that merges both the content and style in a unique way.
Analysis Human Decision Making Process through iEEG data
keywords: iEEG Signals Analysis, Butterworth Filter, XGBoosted Tress, drift diffusion model
date: Jul.2018

The project focuses on the two tasks of firstly localizing the brain regions in which memory and perception decisions are made, and secondly, providing evidence of the drift diffusion process in neural activity during an individuals decision making process.The data involved in this project was collected through experiments involving patients having brain activity read via an Intracranial Electroencephalograph (iEEG). Both traditional signal processing and machine learning tools were utilized in order to achieve the outlined goals. The relevant brain regions were localized through modeling of individual leads, whilst evidence of the drift diffusion process was collected by analyzing multiple machine learning model behaviours over the course of a decision.
Previous research suggests that the decision making process can be modelled as a continuous collection of information (evidence)over time. Such a process, that leads to a binary decision, can be described with the use of the Drift Diffusion Model (DDM) (Ratcliff, 1978). The idea behind this being that, if neuronal activity were to be captured, it would depict the accumulation of evidence over time until it reaches a(decision) threshold (Ratcliff, Smith, Brown, & McKoon, 2016).
About the preprocessing work, a technique called differencing to the raw signal data is applied. Then for all the 125 preprocessed input EEG signals, we manually extract 125*54 features and fit them to a classification tree model. Therefore, if the participant makes a positive decision, the model should output positive result according to the input features; in adverse, when volunteer giving a negative decision, the model should output negative result. As the end, we could not achieve a higher accuracy of 67%. Although it is not a very good result, considering that the project is about human's brain, there is still room left for improvement.
Computer Vision Implementation: Image Stitching
keywords: Image Stitching, SIFT Matching, Homgraphy Transformation Matrix, RanSac Algorithm, Computer Vision, Matlab
date: Jun.2018

A panorama application has been developed to stitch together pairs of images. To minimize perspective distortions, we selected several pairs of parallel images, including iconic landmarks like the Cathedral of Santa Maria del Fiore and the Forbidden City.
The process begins by extracting a set of SIFT descriptors from both images (e.g., 1000 descriptors). These descriptors from the first image are then matched to those from the second image based on their Euclidean distance. Using a threshold, the top 500 matches are selected out of the possible 1000x1000 combinations to serve as candidates for the next step, which involves the RANSAC algorithm. Next, RANSAC is applied over 1170 iterations to these 500 candidate matches to eliminate incorrect pairs. Once filtered, 5 correct pairs are used to compute the Homography Matrix, which determines how to map the coordinates of the matching points from image_1 to image_2, including any necessary rotations to align the matched SIFT keypoints.
The final step involves converting the coordinates of the matched pairs into a unified coordinate system and stitching the correctly matched pairs together using zero-padding. The result is a seamless combined image.
Robotic Localization System Based on Kalman Filter
Keywords: Robotic Localization, Kalman Filter, Real-time Self-localization, Known Global Correspondence, Velocity Based Kinematic System, Pygame
date: Mar.2019
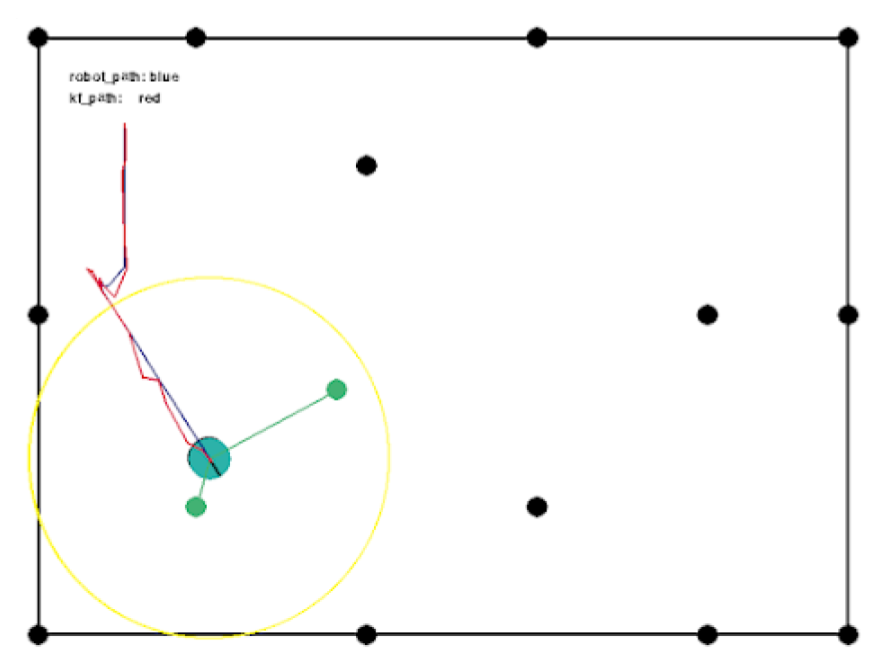
This project aims to build a robotic self-localization system in a given map, so that my robot can track her position after moving at each time step(14 times in every second in this project). My robot works in a known correspondence map, which means each landmark in the map is different with others (spots in the map). By using Kalman filter in this situation, the robot can do both Local Localization(given initial position) and Global Localization (unknown initial position).
The project is constructed in pygame since the robot also needs a real-time outside controller. Spots are the landmarks in the map and yellow circle represents the detection range of the radar. At each time step, localization system works in three main steps: 1) estimating her next position based on its measurement; 2) moving in the map and receiving position measurements; 3) calculating the Kalman Gain and adjusting her estimation, the adjusting result will be used as true current position.
Implement YoloV3 in Tensorflow2.0 with Pre-trained Weights
keywords: Object Detection, Deep Learning, YoloV3, TF2.0
date: Jun.2019
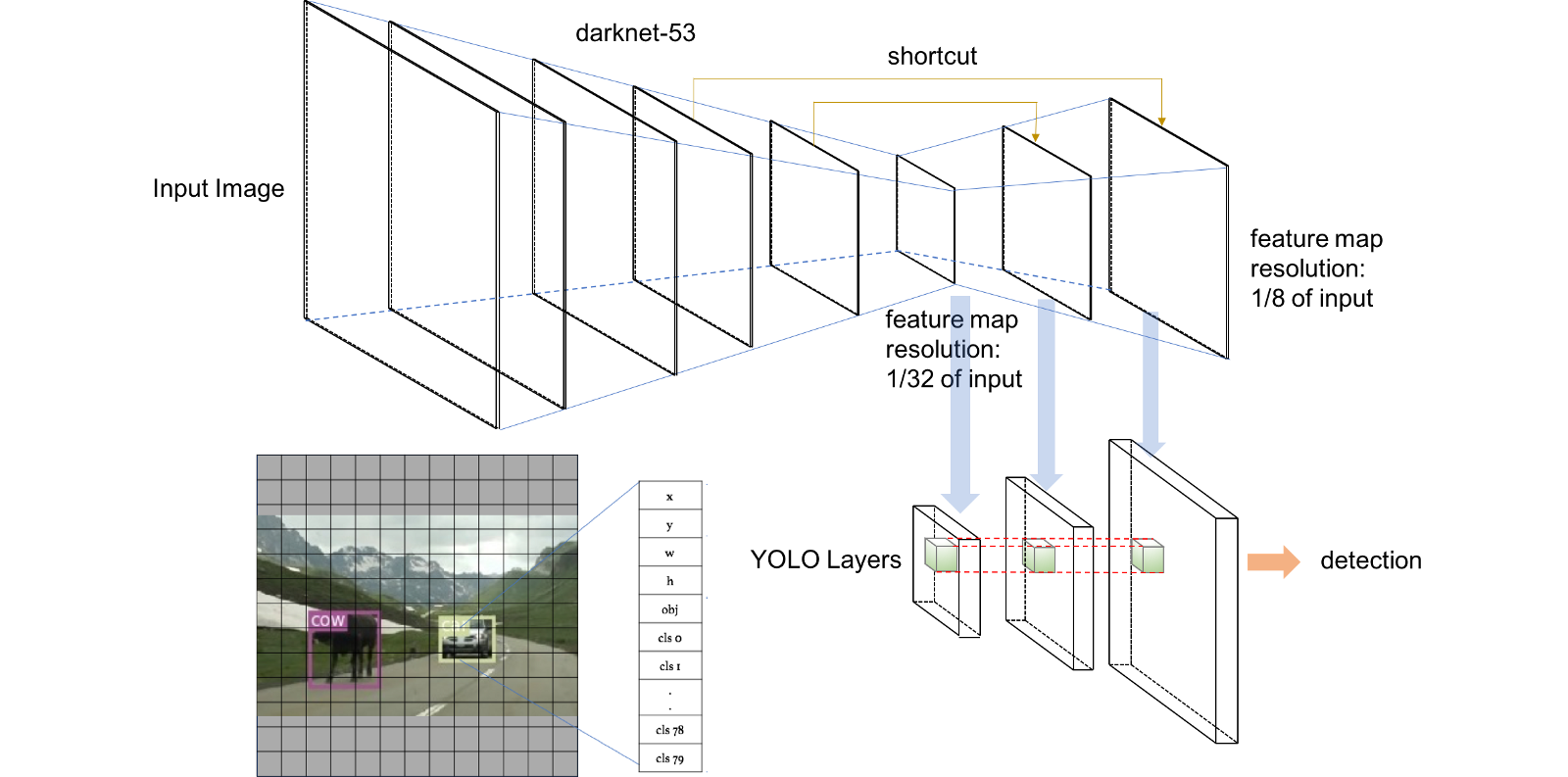
Yolo architecture is one of the most successful deep learning models in object detection, and the newest version is YoloV3(published in 2018).It is able to detect 80 different types of object in the image within 100ms. However, currently all of the available repositories I checked are constructed with tf1.x version. Therefore, I decide to build my own model.
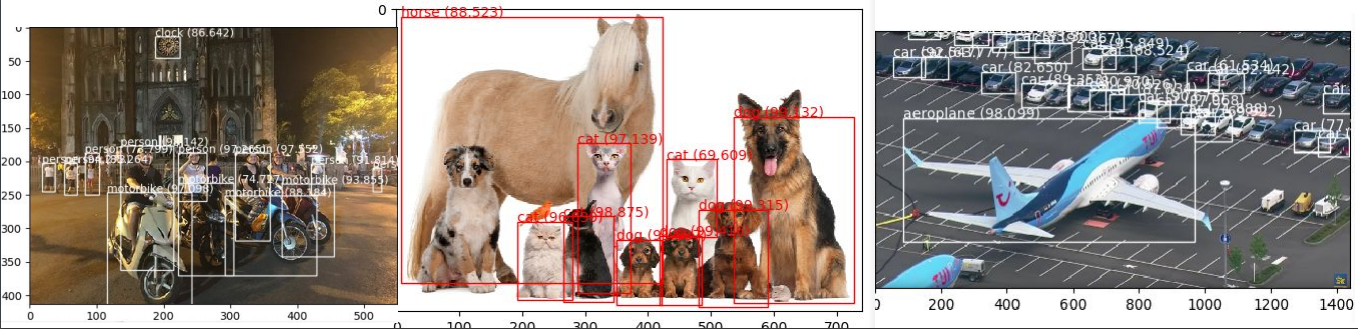
The following figures are the object detection results based on some images downloaded from google. Yolo is a complicated model, and due to the length of this blog, all the details are not given. If you want to get access to my code, please contact me via Github.
Breast Cancer Detection
keywords: Deep Learning, CNN, Cancer Detection, ResNet, Inception, Pytorch
date: Jul.2019

Breast cancer is the one of the most common cancers in the world, about 1 in 8 women are suffering such disease. This project presents a CNN model which aims at diagnosing Breast Cancer through cell images. Moreover, please note that my project just provides a feasible approach, and its result could not be used as the clinical diagnosis.
The dataset consists of more than 7000 labeled breast cell images which are real-world clinical images, including both malignant and benign ones. Therefore the task is to build a covincible deep learning model to do binary classification. Two models are constructed here, by using both pre-trained Inception V3 and Resnet 101 as the backbone. The result shows Resnet gives a better result with accuracy of 93.5%.
By just watching the cell images, I cannot tell the difference between the two classes. Futhermore, some images look relly similar but with different labels, it means the result might be on the brink of malignant. These images will undoubtedly increase the difficulty of training. But suprisingly the model still does pretty well. The whole project is implemented in pytorch, and we still have some space to improve the final model. For instance by using a balanced dataloader, doing K-fold cross-validation training, fine-tuning the decay parameters .etc.
BSPM Signal Completion by Implementing 1D-Convolutional Variational AutoEncoder
keywords: ECG, BSPM, Convolutional Neural Network, Autoencoder, Wavelet Tranform
date: Dec.2018
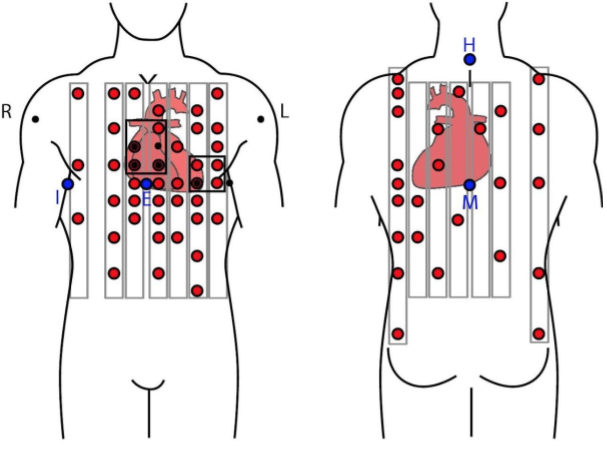
The research of this project is accepted by COMPUTING IN CARDIOLOGY 2019(CINC) as a poster presentation at the conference: Neural Network-Based Matrix Completion for Minimal Configuration of Body Surface Potential Mapping.
Electrocardiography (ECG) is a widely known medical procedure to process the recording of the electrical activity of the heart over a period of time as wave-forms. Today, the 12-Lead ECG system remains a standard diagnostic tool among paramedics. However, the accuracy of the 12 lead ECG has been called accuracy questions. Many studies have proved that by using the Body Surface Potential Map system(BSPM), more accuracy is gained. Although superior in terms of their diagnostic yield, BSPM is still not widely used in clinical practice(shown in figure 1) due to not only the lack of standards but also guidelines for performing a BSPM procedure. Moreover, the complexity of measurement and analysis increases greatly when using more electrodes.
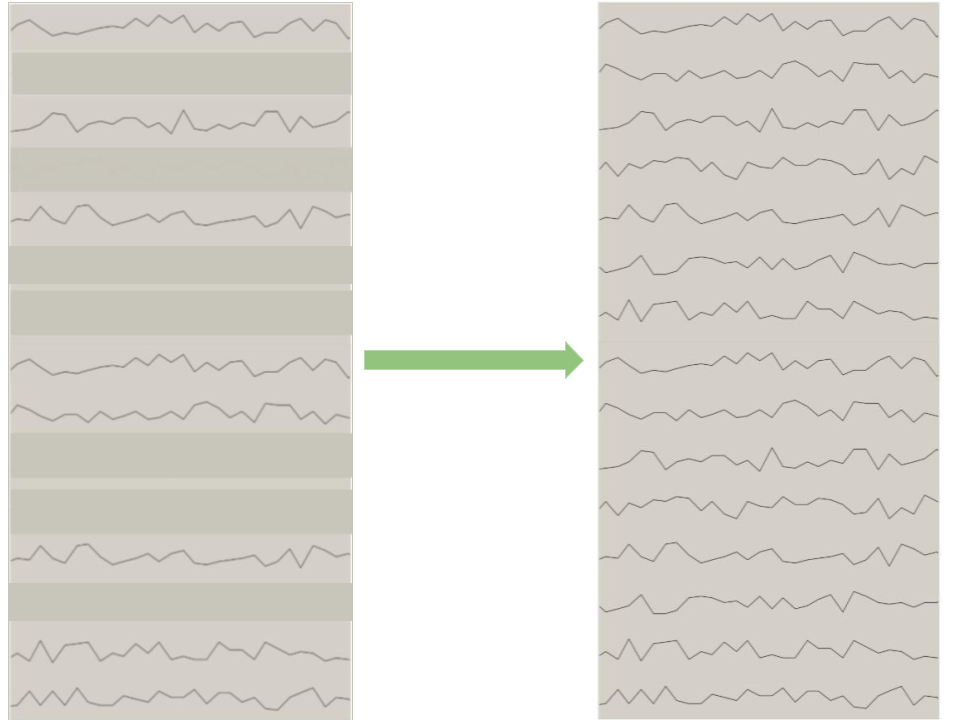
The aim of this research project is to reconstruct lead recording of BSPM procedure by implementing artificial neural networks over limited BSPM leads data. With the pre-trained model, we only need to input heartbeat signals from 12 sensors, then we can receive the BSPM result with 64 channels.
Twitter Sentiment Analysis
keywords: NLP, Sentiment Analysis, Tweet Analysis, TF-IDF, BoW, Logistic regression.
date: Jul.2018

This project aims at analyzing the sentiment and topic for a bench of tweets, the dataset consists of more than 1.2 million tweets, and all of them were posted in 2016 from users in Nederland and Belgium. Data will be splited into 12 groups according to the post month, eventually we are able to do: 1). Estimate the most popular topics in each month; 2). Tell you which month is the happiest month and which one is the saddest in 2016.
All data has to be well preprocessed firstly since tweets contain too much noise like web links, symbles and emojis. Considering that a large part of emojis might almost represent the sentiment of the tweet, for example "what I felt when watching the movie 🤩", all the emojis are converted to words instead of deleting them. After tokenization and lemmatization, tweets are represented by TF-IDF and BoW(two approaches). Then the sentiment is decided by a pre-trained tweet sentiment logistic model. By using the tf-idf vectors, we reach the precision with 82%.
Top 150 Football Player's Salary Analysis Based on 2018 Official FIFA Dataset
keywords: Knowledge Graph Model, Talent Football Player, Regression Tree, Salary Analysis
date: Apr.2019
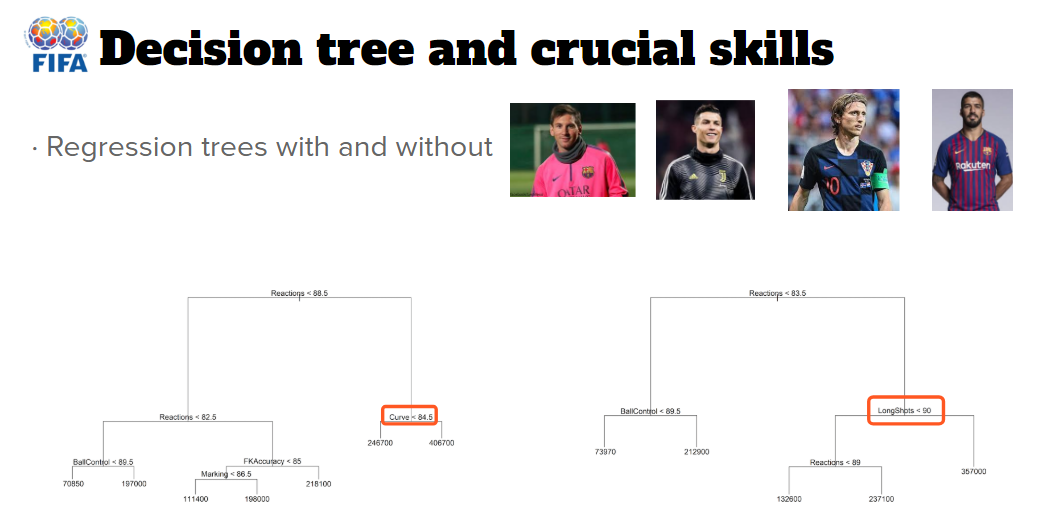
Football is generally considered as the most popular sport throughout the world. When events such as the World Cup and UEFA (Union of European Football Associations) European Championships are held, the related information is concentrated in the news and print media. Among the most widely discussed topics are the professional football players, and consequently considerable research on copying the success of the talents are already underway.
The project has two main tasks: 1). constructing a knowledge graph model to learn the indirect inter-relationships between the talent players, the corresponding countries and clubs; 2). Building a reasonable salary regression according to their abilities, so that we can find the behind reasons that why these players are successful and valuable.
The dataset consists of 18,206 samples belonging to football players who were registered in FIFA 2018. Each player has 89 different kinds of information, including basic information, position evaluations and skill scores. For knowledge graph model, top 450 football players are selected based on the lattest FIFA ranking list, then 71 attributes are extracted (shown in Table 1) and converted to RDF datatype. While for salary model, only top 150 football players are picked since their income are considered at the high level in this field.
Security Check through Gait Analysis
keywords: Gait Analysis, Deep Learning, Data Science
date: Sep.2019
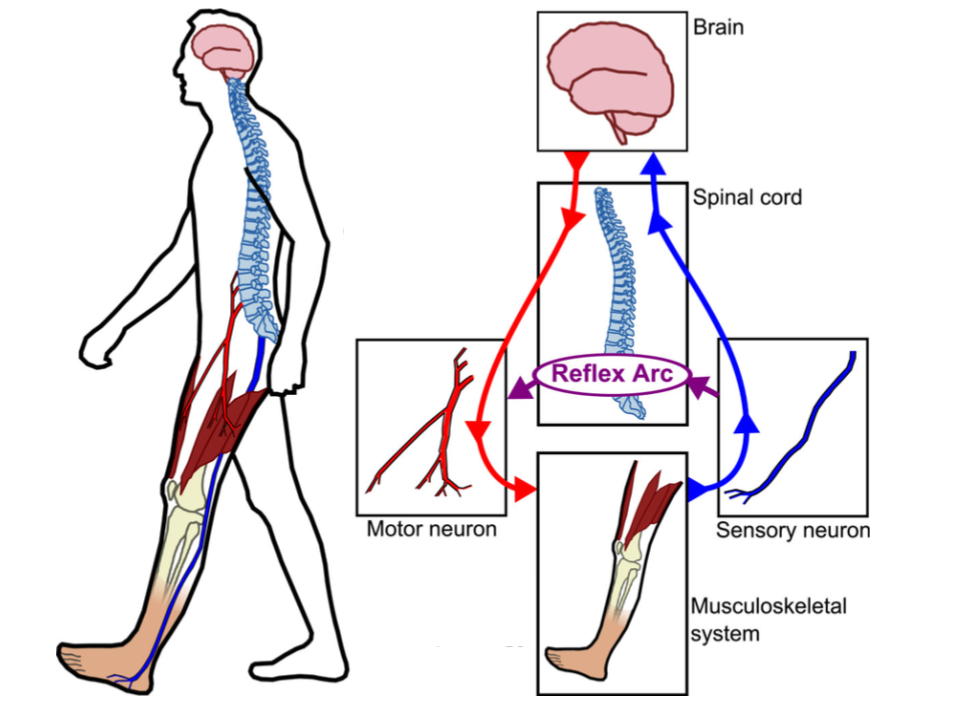
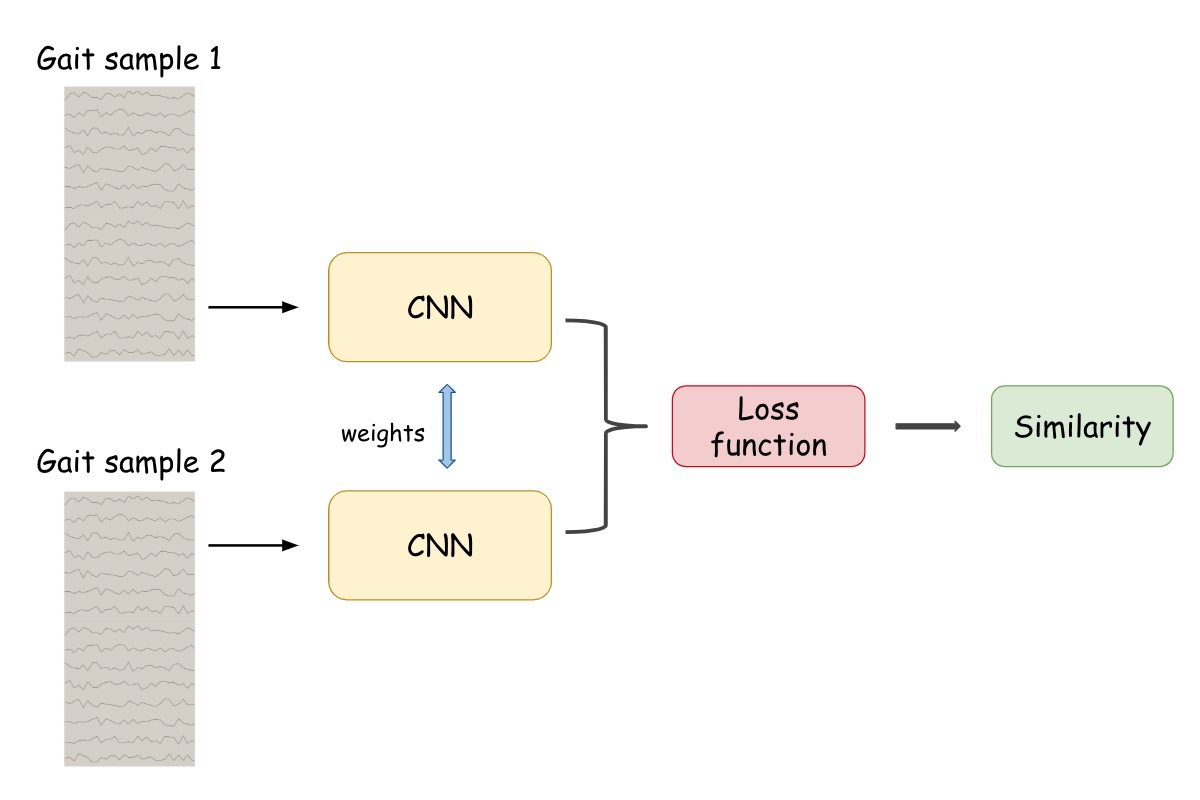
Gait Analysis is also known as Human Locomotion research. Previous study has proved that human's gait is private, stable and unique feature, and importantly it’s very difficult to imitate. Accordingly, in the last decade there has been an increasing interest in gait analysis based biometric authentication. In general, related research falls into two domains: (1) gait image or vedio based study and (2) gait signal based study. In this project, we draw our attention to the latter topic. We manage to use gait signal from only one sensor to do the authentication task, which means in the future we can implement such model on mobile phone, wearable equipments or even vehicle keys. And suppose that the imposters or thieves could be automatically detected by the gait data which is automatically collected within a few seconds, is that cool?
The system employs siamese archictecture with 1D-CNN as its backbone. The behind idea of our authentication system is similar to the face recognition system, but based on gait signals. We have achieved a huge progress in late October 2019, with a pretty nice result of 0.2% training Equal Error (EER) Rate and 1.8% test EER. Our GaitNet outperforms current state-of-the-art models in gait authentication. Besides training the gait authentication model, we also build a quantization workflow which successfully quantize the model to 4-bit representation without losing significant accuracy (test EER of 2.76% ).
Flappy Bird AI player
keywords: Reinforcement Learning , Deep Learning, Intelligent Game, Computer Vision
date: Dec.2019
This project aims at training an AI player for the game "Flappy Bird"
Elephant Detection Based on YOLOv5
keywords: Deep Learning, YOLOv5, Object Detection, Pytorch
date: Aug.2020
YOLOv5 v2.0 is released on July 23, 2020! Compared with YOLOv3, YOLOv5 is faster and more accurate. Therefore I'm eager to train a customised YOLOv5 on Pytorch. This project aims at training an elephant detection model.
The dataset consists of 1700 labeled elephant images, with the format of "YOLOv5 dataset format". Moreover, according to my experiments on training an elephant detector and a clothes detector, 300~500 epochs training seems to be enough for a customised YOLOv5. Training such elephant detector takes 30 minutes on RTX 2080ti GPU. The below figure shows the prediction on three elephant images downloaded from google.

Anomaly Detection in Robotic System Deployment Using Docker and Flask
keywords: Anomaly Detection, Model Deployment, Feature Extraction, Wavelet Transform, Unsupervised Learning, Flask, Docker
date: Sep.2020
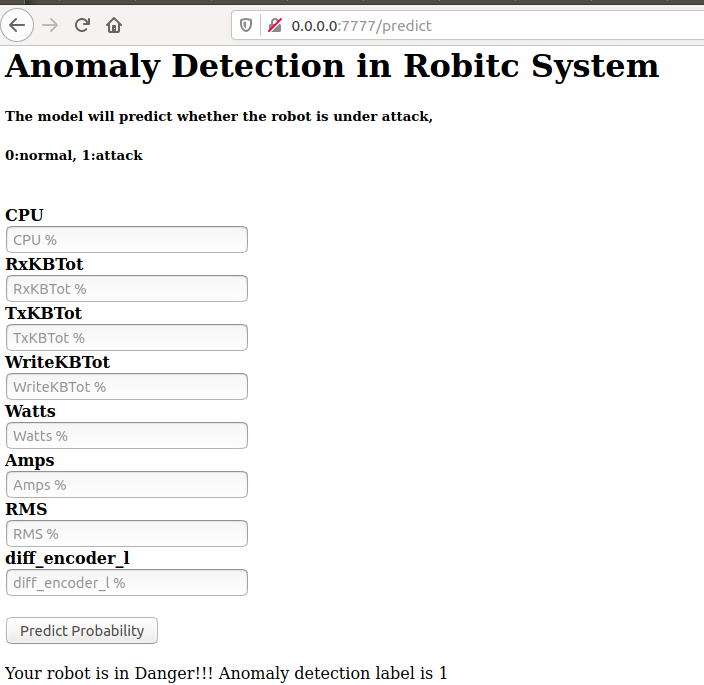
In this post, we will build an Anomaly Detection API for 5G robotic signals by using FLASK and Docker. The original dataset is 8-channel timeseries captured by robotic sensors. Our aim is to build anomaly detection model to determined whether the robot is under attack at every timestep. Although we have label for each timestep, we should pretend there is no label (that's the rules, it sounds odd I know :).
The whole report is divided into five parts: (1)data preprocessing by using wavelet transform and feature extraction; (2) un-supervised clustering; (3) building classification tree and support vector machine based classifiers; (4)building and training neural network based multilabel classifier and (5) model deployment with Docker and FLASK.
LSTM AutoEncoder based Anomaly Detection Model for Multi-channel Timeseries
keywords: LSTM AuotoEncoder, Deep Learning, Anomaly Detection for Multi-channel Timeseries
date: Oct.2020
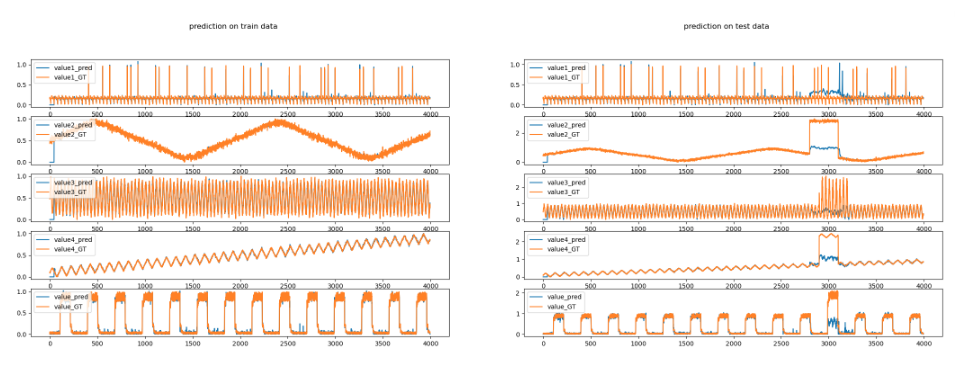
In previous post, I built an Anomaly Detection API for 5G robotic signals based on SKlearn framework. The Docker API is cool, but there is still some space to improve the model. Therefore in this post I will build LSTM prediction model and LSTM autoencoder to do anomaly detection for a muti-channel timeseries data set, which has 5 channels and is more complicated. Due to the limited resource of multi-channel timeseires dataset for anomaly detection research, the data set used in thi post is generated myself.
Two models are built in the study, a normal timeseries prediction LSTM model and a LSTM autoencoder. The figure above is from the prediction model. The model is firstly trained by a set of sliding windows which are extracted from the clean data set (without anomalies). After training, we set the anomaly decision threshold by calculating the highest distance between the prediction and the groundtruth. Last we test the model by using the anomaly dataset, and from the right figure we can clearly see that the prediction for anomaly samples are very different from the normal samples. By the way, the LSTM autoencoder has better performance than the prediction model in our study, the result of figure is not given as the figure is not intuitive as the prediction model.
Transformer based Movie Genre Prediction
keywords: NLP, Transformer, Movie, Multi-label prediction, Pytorch
date: Jan.2021

Transformer model architecture is supposed to be one of the biggest milestone in NLP research in recent years. There are many famous models in the Transformer family, such as Bert, GPT, T5 ,etc. In this project, I build a BERT based model to predict the movie genre according to the synopsis.
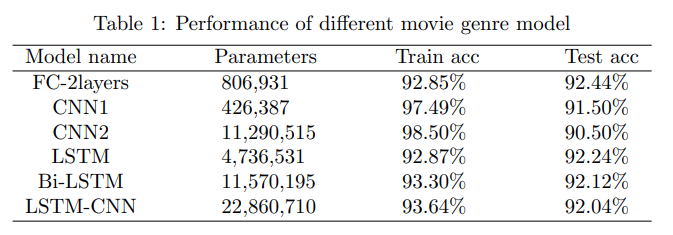
In the data set, there are 36,518 samples. 88 percent are used to train the model, and the rest 12 percent are test data. The label consists of 19 different movie genres, including: 'Drama', 'Horror', 'Thriller', 'Children', 'Comedy', 'Romance', 'Action','Adventure', 'Crime', 'Film-Noir', 'Documentary', 'War', 'Fantasy','Animation', 'Mystery', 'Western', 'Sci-Fi', 'Musical', 'IMAX'. Therefore it's a multi-label classification question. A few models are built in order to get the optimized one, like BERT+FC model, BERT+1D-CNN, BERT+LSTM, BERT+(1D-CNN+LSTM). The performance of each model is shown in the table below, and the result shows that BERT+FC does pretty well. Although not the best performed one, the training only takes 0.5 GPU hours on RTX 2080ti, while others need at least 3 GPU hours. Moreover, I also notice that the accuracy for genre 'Drama' and 'Comedy' are really low, about 80%, this is probably because the synopsis cannot provide enough features for these two labels. The future work is: (1) add some features to every synopsis of 'Drama' and 'Comedy' movie, and (2)train the model again to see whether we have higher accuracy.
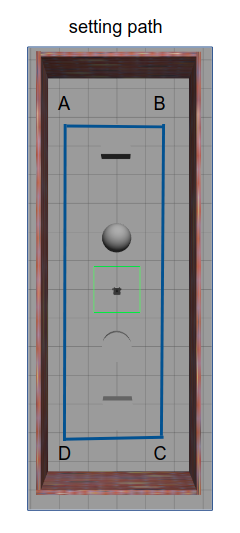
ROS Turtlebot3 SLAM and Path Planning
keywords: ROS, Turtlebot3, SLAM, Path Planning
date: Mar.2021
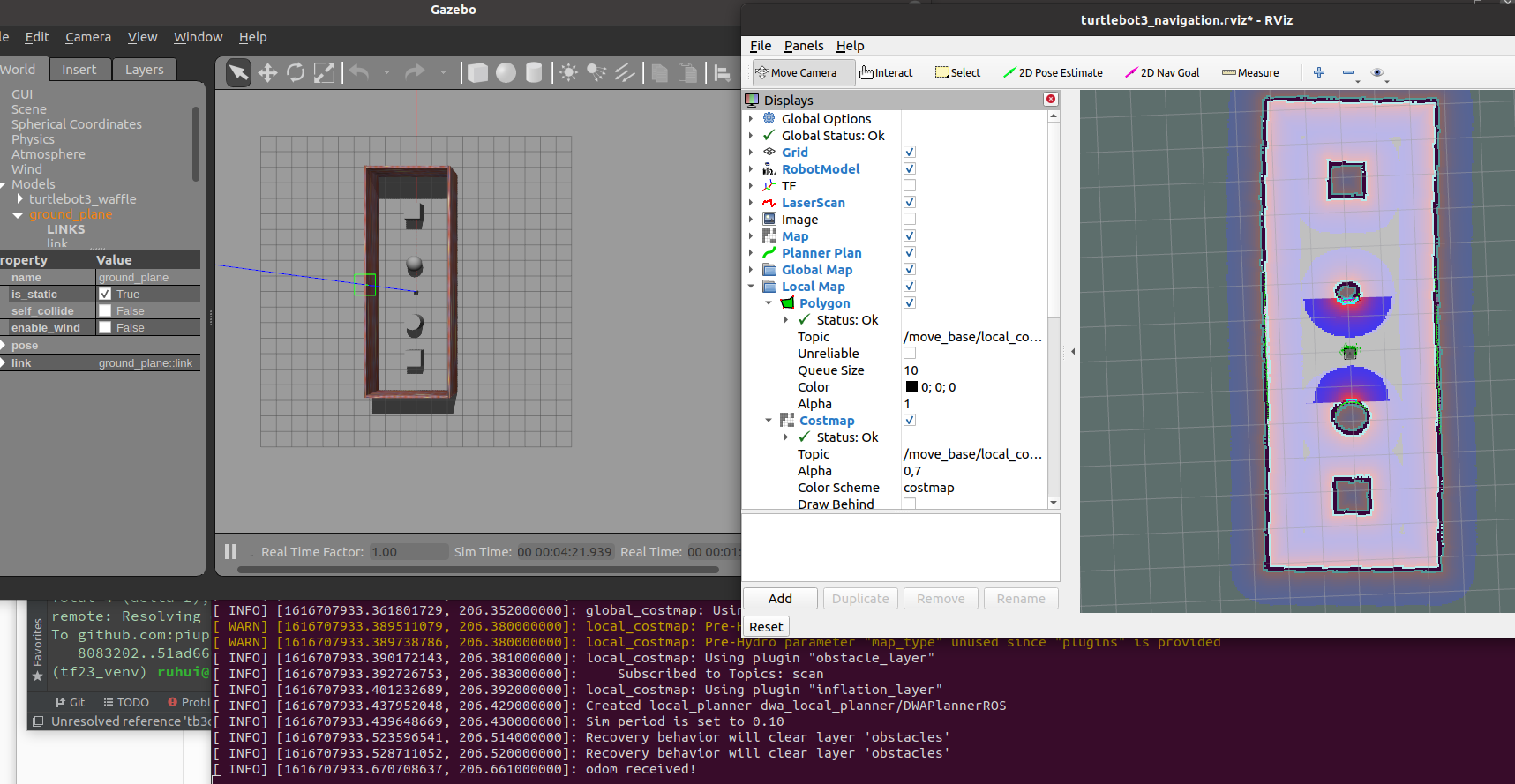
The robot will definitely become the game-changer in the era of industry 4.0, which means roboic engineer might be in high demand over the next few years. Therefore it's better to learn some ROS now! If the future was not as we expected, no worries, we can still use ROS skill to program a home robot or robot toy for kids ... In this project, I implement a turtlebot3 path planner, which let the robot roam in the room along the path A-B-C-D-A-B-C-D ... The task is done by using ROS turtlebot3 simulator since I don't really have a robot :(